Scalable Python Application Deployments on AWS OpsWorks
Here at Jazkarta we’ve been creating repeatable deployments for Plone and Django sites on Amazon’s AWS cloud platform for 6 years. Our deployment scripts were built on mr.awsome (a wrapper around boto, Python’s AWS library) and bash scripts. Our emphasis was on repeatable, not scalable (scaling had to be done manually), and our system was a bit cumbersome. There were aspects that were failure prone, and the initial deployment of any site included a fair amount of manual work. When we heard about AWS OpsWorks last summer we realized it would be a big improvement to our deployment process.
OpsWorks
OpsWorks is a way to create repeatable, scalable, potentially multi-server deployments of applications on AWS. It is built on top of Chef, an open source configuration management tool. OpsWorks simplifies the many server configuration tasks necessary when deploying to the cloud; it allows you to create repeatable best practice deployments that you can modify over time without having to touch individual servers. It also lets you wire together multiple servers so that you can deploy a single app in a scalable way.
OpsWorks is a bit similar to PaaS offerings like Heroku but it is better suited for sites that need more scalability and customization than Heroku can provide. The cost of Heroku’s point and click simplicity is a lack of flexibility – OpsWorks lets you change things and add features that you need. And unlike the PaaS offerings, there is no charge for OpsWorks – you don’t pay for anything besides the AWS resources you consume.
Briefly, here’s how it works.
- First you create a stack for your application, which is a wrapper around everything. It may include custom chef recipes and configuration and it defines the AMI that will be used for all the instances. There are currently 2 choices, latest stable Ubuntu LTS or Amazon Linux. (We use Ubuntu exclusively.)
- Within the stack you define layers that represent the services or functionality your app requires. For example, you might define layers for an app server, front end, task queue, caching, etc. The layers define the resources they need – Elastic IPs, EBS volumes, RAID10 arrays, or whatever.
- Then you define the applications associated with the layers. This is your code, which can come from a github repo, an S3 bucket, or wherever.
- Then you define instances, which configure the EC2 instances themselves (size, availability zone, etc.), and assign the layers to the instances however you want. When you define an instance it is just a definition, it does not exist until it is started. Standard (24-hour) instances are started and stopped manually, time-based instances have defined start and stop days and times, and load-based instances have customizable CPU, load or memory thresholds which trigger instances to be started and stopped. When an instance starts, all the configuration for all the layers is run, and when it is stopped all the AWS resources associated with it are destroyed – aside from persistent EBS storage or Elastic IPs which are bound to the definition of the instance in OpsWorks instead of being bound to an actual instance.
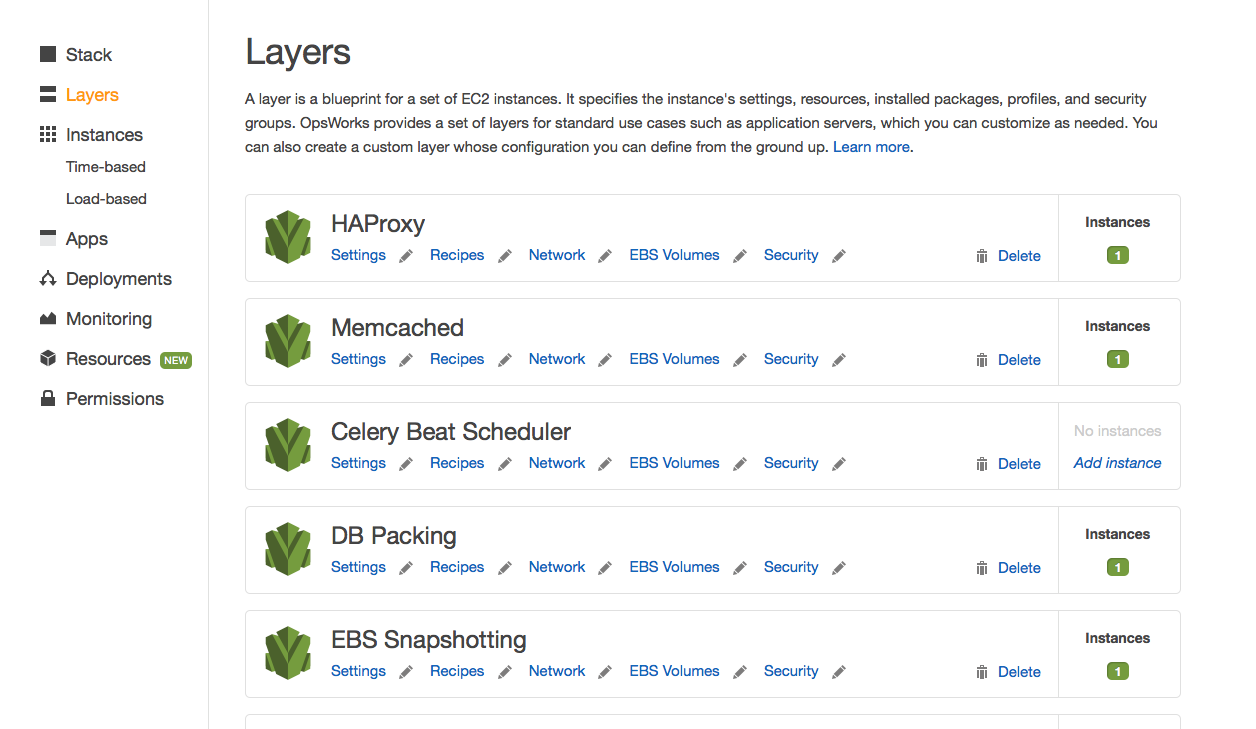
Managing Layers

Managing a time-based autoscaling instance
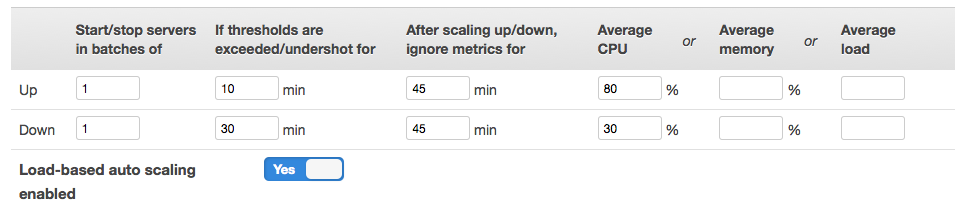
Managing a load-based autoscaling instance
For more details and a case study about switching from Heroku, see this excellent introduction to OpsWorks by the folks at Artsy.
What We Did
OpsWorks has native support for deploying Ruby on Rails, NodeJS, Java Tomcat, PHP, and static HTML websites, but no support for Python application servers (perhaps partly because there is no standard way to deploy Python apps). This was a situation we thought needed to be remedied. Furthermore, few if any PaaS providers are suitable for deploying the Plone CMS which many of our clients use. Because OpsWorks essentially allows you to build your own deployment platform using Chef recipes, it seemed like it might be a good fit.
Chef is a mature configuration management system in wide use, and there are many open source recipes available for deploying a variety of applications. None of those quite met our needs in terms of Python web application deployment, so we wrote two new cookbooks (a bundle Chef recipes and configuration). We tried to structure the recipes to mimic the built in OpsWorks application server layer cookbooks.
The repository is here: https://github.com/alecpm/opsworks-web-python. Each cookbook has its own documentation.
- Python Cookbook – provides recipes to create a Python environment in a virtualenv, to deploy a Django app, and to deploy a buildout
- Plone Cookbook – builds on the Python and buildout cookbooks to deploy scalable and highly available Plone sites
The Plone cookbook can handle complex Plone deployments. An example buildout is provided that supports the following layers:
- Clients and servers and their communication
- Load balancing
- Shared persistent storage for blobs
- Zeoserver
- Relstorage – either via Amazon RDS or a custom database server in its own OpsWorks layer (there is a built in layer for MySQL)
- Solr
- Redis and Celery
- Auto-scaling the number of Zeo clients from the AWS instance size
The recipes handle automatically interconnecting these services whether they live on a single instance or on multiple instances across different Availability Zones. For more information, see the README in each cookbook.
What’s Next
We’ve used OpsWorks with our custom recipes on a few projects so far and are quite happy with the results. We have a wishlist of a few additional features that we’d like to add:
- Automated rolling deployments – a zero down time rolling deployment of new code that updates each Zeo client in sequence with a pause so the site doesn’t shut down.
- Native Solr support – use the OS packages to install Solr (instead of buildout and collective.recipe.solr) and allow custom configuration for use with alm.solrindex or collective.solr in the recipe.
- Integration of 3rd party (New Relic, Papertrail, …) and internal (munin, ganglia, …) monitoring services.
- Better documentation – we need feedback about what needs improvement.
If you’d like to contribute new features or fixes to the cookbooks feel free to fork and issue a pull request!
Trackbacks
- THIS WEEK IN AWS, JUNE 11 2014 – This Week In AWS | Amazon Web Services
- New KCRW Website Launched | Jazkarta Blog
Comments are closed.



Thanks for your great post.
I’m using Elastic Beanstalk to deploy my django app. I’m really upset because EB doesn’t runs fine…sometimes it shutdowns and starts new instances without any reason, sometimes a source bundle app isn’t well deployed and sometimes is it, etc. so far, I’m looking for other solutions. Over my desk I have:
1. Use boto and fabric and make deployment directly on aws resources.
2. Use OpsWorks
As you commented, python is not supported “native” in OpsWorks. Do you use OpsWorks and mr.awsome/boto combined?
Hi Roger,
OpsWorks is built around Chef, so we are using custom Chef cookbooks to manage deployment of python applications. There is no dependence on mr.awsome/boto, which is what we used previously for our EC2 deployments. At this point we do all of our server management/deployment through the GUI (with some initial setup using CloudFormation templates), but it’s also possible to use boot to control OpsWorks.
The builtin OpsWorks cookbooks provide Application Server configurations for Ruby, Node.js, PHP, Java and static sites, but not for Python. There are community chef cookbooks for Python apps, but they are structured a bit differently from the way OpsWorks structures its application server cookbooks. Our cookbooks attempt to provide that functionality in a manner consistent with OpsWorks deployments and are Open Source; however they should probably still be considered beta, or perhaps alpha as far as Django deployments are concerned.
The goal is to have the cookbook defaults provide deployment best-practices out of the box for Plone, Django and eventually Pyramid applications. I’m most familiar with Plone and buildout deployment practices, so that’s where much of the effort has gone up to this point. I would say that if your deployment is fairly standard, or if you don’t mind learning a bit of Chef/Ruby to customize it, and you need to be able to easily separate our functionality onto multiple instances, OpsWorks is a great option. I would also suggest looking into Ansible, as an alternative to boto + fabric, if you want to deploy directly on EC2 using Python.
I am very very new with Ops Works and do not know a lot about CHEF. My first task is to deploy a python application on a custom layer. I think that I can use this recipe but am not sure how to implement. Any tips for a newbie like me on how to go about doing the task. Any help is greatly appreciated
What sort of python application. There are a few different recipes in the cookbook(s) depending on the type of application. The recipes have primarily been tested for Plone and buildout based applications as well as a bit with Django applications. The generic python deployment recipe is pretty bare bones, but should be a good starting point for other types of python apps. The README in the opsworks_deploy_python cookbook directory should cover the basics.
Hey,
Thanks for the blog post. It is very interesting. I am trying your cookbooks on my OpsWorks stack, but I am having a problem when running opsworks_deploy_python::default recipe in Setup step. This is the error I am getting:
================================================================================
Recipe Compile Error in /var/lib/aws/opsworks/cache.stage2/cookbooks/packages/attributes/packages.rb
================================================================================
TypeError
———
no implicit conversion of Symbol into Integer
Cookbook Trace:
—————
/var/lib/aws/opsworks/cache.stage2/cookbooks/packages/attributes/packages.rb:19:in `from_file’
Relevant File Content:
———————-
/var/lib/aws/opsworks/cache.stage2/cookbooks/packages/attributes/packages.rb:
12: # would completely override this file and might cause upgrade issues.
13: #
14: # See also: http://docs.aws.amazon.com/opsworks/latest/userguide/customizing.html
15: ###
16:
17: # Toggle for recipes to determine if we should rely on distribution packages
18: # or gems.
19>> default[:packages][:dist_only] = false
20:
21: include_attribute “packages::customize”
22:
Am I missing a configuration or something like that? I would really appreciate any help as I am very new to Chef and OpsWorks!
Thanks a lot 😉
It looks likely that you set a global attribute node[‘packages’] to an array value (probably in the stack custom JSON or in your own recipes), which broke the built-in packages cookbook (which appears to expect a hash value for that attribute). You probably intended to set node[‘deploy_python’][‘packages’], or node[‘deploy_python’][‘os_packages’], or better yet node[:deploy][‘$your_app_name’][‘packages’].